基础知识
生成模型
生成模型作为深度学习的一个领域,我觉得首先就是要搞清楚模型输入是什么,输出是什么。对于目前火热的根据文字生成图片的应用,可能会认为输入就是文字,而输出就是图片。
但只要仔细想一下就会发现不对,如果是输入文字输出图片,那为什么相同文字可以输出不同图片?这个模型在训练时的损失函数是什么?如果是真实图片与生成图片之间的损失,那我们训练岂不是一个编码器,把文字编成图片?那这生成了个什么呢?
实际上,文生图已经是生成模型的多模态应用了。一般的生成模型,其输入是一个服从某个分布(一般是高斯分布)的随机噪声,其训练的并不是一个固定的编解码器,而是一个概率分布,输出的图片是根据随机噪声, 在训练得到的概率分布采样得到的。而训练过程中的损失函数,虽然形式多有不同,但是其本质上都是训练得到的概率分布与真实概率分布之间的误差。
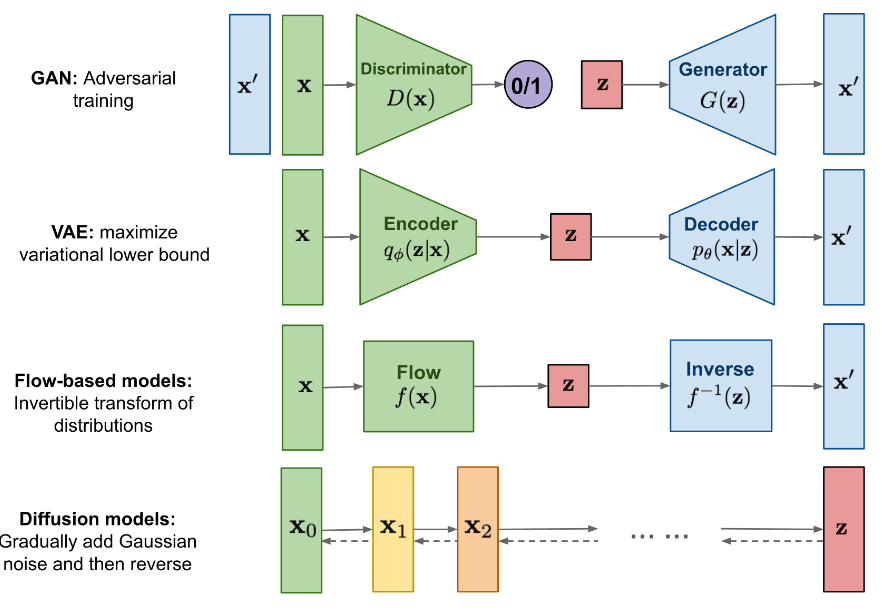
接下来这张图是一张被抄了无数次的图,介绍了常见生成模型的结构,原地址应该是这个 ,这位作者的博客里还有很多很好的文章,都挺通俗易懂的,不介意看英文的建议直接关掉这篇文章,去看上面链接的大牛写的东西。

上面的就是随机噪声,是真实图片,是生成图片。前三个GAN、VAE和Flow-based models都挺好理解的。当然,如果完全没接触过的话其实也没那么好理解,这里简单介绍一下。注意,这里介绍的相当简单,生成模型背后都是有概率原理的,建议自己去看一下。
正如前面所说,生成模型学习的是一个概率分布,最简单的想法就是我们直接把概率分布学出来就完了,这就是Flow-based models的思想(上图的第三个嗷,不是第一个),他利用normalizing flows(中文不知道叫啥)通过一系列变换直接学到真实数据的分布,生成时采样一个,然后通过逆变换还原出。听起来很简单,但实际上真实的分布是很复杂的,他能这样学是因为做了很多限制,导致Flow-based models的生成效果并不好。
既然真实分布不好学,我们可不可以学一个好学习的分布,然后利用这个分布导出真实分布呢?比如我现在知道噪声的分布(为什么知道呢,因为的分布是你假设的,你想是啥就是啥),那我可不可以去学一个,条件分布肯定比整体的分布好学嘛,然后对吧,这就是VAE(变分自编码器,上图第二个)的基本思想。当然实现细节要比这复杂的多,比如他既然叫变分自编码器,那自编码就有Encoder和Decoder,上面的思想只是Decoder的思想,Encoder为什么学的是呢?另外上图给VAE的注释是最大化变量下界是什么意思呢?这里只简单提一下,Decoder是生成器,在生成图片的时候确实是只用他,在训练的时候Encoder和Decoder是一起训练的;VAE他和普通AE(自动编码器)的区别是VAE的Encoder输出不是编码,而是一个分布,是从这个分布中采样得到的,学习是有数学上的考虑的,详细的可以去看其他文章里的推导,推荐上面那位大牛的博客或者苏剑林大佬的博客。至于什么是最大化变量下界,涉及数学上对VAE损失函数的推导,因为VAE对分布的学习都是通过神经网络学的,那你怎么去衡量一个神经网络学出的概率分布的损失呢,毕竟概率分布又不是个向量,也不是个矩阵。其实生成模型复杂的数学推导都是在推导损失函数,详细的后面再说。
上图第一个就是大名鼎鼎的GAN了,相信这个原理大家随便找篇文章都能看懂,就是生成器和判别器之间互相进化。GAN巧妙的点在于它规避了生成模型训练得到的分布难以直接进行评判(也就是设计损失函数)的问题,我直接设计一个神经网络去评判就好了。GAN的问题也很明显,就是生成器和判别器不是同步训练的,两个网络的损失函数是不同的,造成训练过程很不稳定,容易崩溃。
哦对了,VAE的缺点忘说了,传统VAE的缺点是生成图像的质量不高,很糊,没办法,真实世界的分布太复杂了,VAE的模型复杂度是不够的
而对于扩散模型,也就是最下面的一个,乍一看,这什么玩意儿,双向链表?网络呢?别急,后面再说。
概率论相关知识
上面介绍VAE的时候说过了生成模型复杂的数学推导都是在推导损失函数,中间是涉及到一些概率论知识的,不过不多,下面就简单介绍一下,甚至不需要小标题。
首先是似然法,也就是课本里的最大似然估计。通俗来讲,似然估计是在知道概率模型(也就是知道公式)的基础上确定参数的方法,怎么估计呢,就是对于已经发生的事情,我们希望他发生的概率越大越好。由于我概率论不好,当时学的时候也只会做题,就记得个取对数,求导,导数为0,所以看到别人推导公式的时候是有点懵的。对于随机变量的概率密度函数(后面就写简写PDF了),是发生的事件,才是发生的概率。所以在进行最大似然估计的时候,对每一个样本,就是要尽可能大,这也是一般生成模型推导损失函数的第一步为什么都是在求的下界,因为下界越大越大。这里我一开始反正是没反应过来,所以记录一下。
之后就是涉及条件概率的一些公式,主要是两个,第一个是条件概率定义
第二个是贝叶斯公式
贝叶斯公式的一个重要的作用是把条件概率的条件和事件(我不知道这里专业的表述是什么,反正就是竖线前面和后面的事件)换个位置。一般情况下,我们也是不知道和的,但是我们可能知道在某一个条件下的和,此时贝叶斯公式的形式为
这种形式的贝叶斯其实更常用,现实生活中一个事件在没有任何条件下的先验本来就很难获得。对于数学带手子这里的推导其实一眼就能看出来,但是我初学的时候确实看了半天没反应过来,所以记一下
接下来就是马尔可夫链。马尔可夫链是指状态空间的变化过程中下一状态的概率分布只能由当前状态决定,也就是无记忆性。扩散过程我们假设是符合马尔科夫链性质的,这个性质在公式推导过程中主要就是计算条件概率时,可以在条件后面修改事件,假设时刻的状态是,那么有
A可以是任意事件。
最后一个就是期望公式,对连续型随机变量,其PDF为则期望为
依然假设,现在有一个关于的函数,则的期望为
注意E的下标的这个记号,又是可以省略自变量简记为,对这种其实就相当于把积分符号和概率乘给写到的下标上,在后面的推导中实在看不懂的话可以给他写成概率乘然后积分的形式。
扩散模型
通俗理解
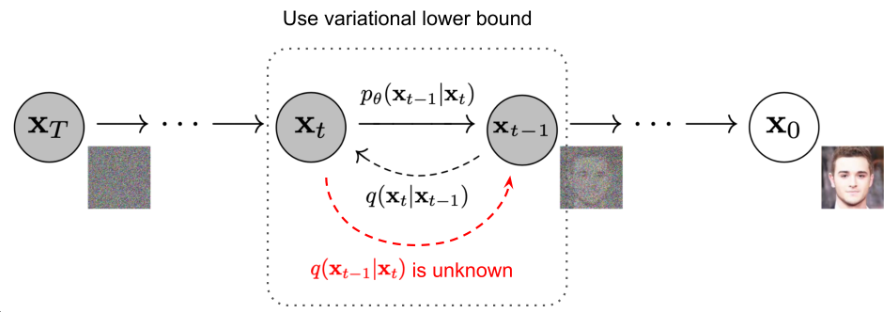
扩散模型的图示就是上图的第四个,这里再放一个官方图
这里往右的箭头是生成的过程,时刻状态是一个各向同性的高斯噪声,时刻则是一张图片。其生成过程就是对高斯噪声逐步去噪,最后生成图片,显然生成的关键就在于如何从到。
扩散模型还有一个过程称为扩散过程,扩散过程是从数据集图片一步步模糊为各向同性高斯噪声的过程,这个过程中我们可以利用上面说到的公式以及马尔可夫性质,建立每一个状态与之间的数学表达式,换句话说,给定和,就可以得到,因此推导过程中不需要用到这个变量。
接下来是一个很粗糙但很通俗的扩散模型解释:训练过程中模拟扩散过程,随机采样一个和一个,通过学习一个网络,网络用于预测噪声。生成过程利用噪声预测网络去噪。算法伪代码如下
伪代码基本就是说的上面这个意思,不过给生成过程起了个名字叫采样过程。
数学推导
下面的推导都是抄的链接,加一些自己的思考。
在此之前,介绍一个重要方法,叫参数重整化。因为在生成模型中涉及很多从分布中采样的步骤,而采样这个步骤是不可导的,但是有的时候我们需要对分布进行调整,这就需要利用参数重整化。例如,对一个高斯分布采样(参数重整化基本都是对高斯分布做的),但是我们需要调整高斯分布的和,我们可以从标准高斯分布中采样一个点,然后令,将作为真正的采样结果,这样梯度就可以传递到和上了。除了传播梯度以外,普通采样也可以使用参数重整化进行,上面伪代码的采样过程就是利用的参数重整化
注意,虽然我们推了一堆公式,但是这些公式最终都是为了推导损失函数服务的,记住这一点就不会乱。我们首先推导需要对什么物理量进行建模,然后证明损失函数下界
扩散过程
首先咱们要推导的就是扩散过程的一个重要性质,即给定和,就可以得到。
先对扩散过程进行建模。假设,定义扩散过程为在步中,每一步增加一个高斯噪声,这样就形成了一系列的噪声采样,每一步加的噪声的大小由确定。即
其中是一个服从高斯分布的随机噪声,那么可以写出
这个公式是多维随机变量的高斯分布,所有有个矩阵,不难发现新的状态和上一状态的区别由控制,具体可以把为0和为1带进去看。根据上面对扩散过程的建模,我们引入,将简记为,然后开始推导
写到这里基本,对于和有关的项,咱们基本上就可以确定大概率是个什么规律了,也就是说结果中必然有一项,对于后面的是什么,首先需要复习一下高斯分布的一些知识。
对于两个高斯分布和,两者的和为,现在是一个服从标准高斯分布的随机变量,当然可以加起来啦
多算两项就能发现其实项也是有规律的,所以
上面的表达就是扩散过程中我们可以得出的结论,理论方面,这个公式后面会用到;实践方面,由于是提前设定的,所以是可以提前全部算出来存在表里的。
采样过程
采样过程需要推导出我们需要训练的PDF的形式。
下面对采样过程进行建模。对于输入的一个服从标准高斯分布的噪声,我们需要根据逐步去噪,最终得到一幅图片。假设也是一个高斯分布,这一步直接看可能有点突兀,虽然文中给出了理由,即正向过程中每一步的改变很小,而,所以可以认为也是一个高斯分布,但总感觉最后结果也会学到一个正态分布。这里要注意我们想得到的是,是一个条件概率,他是高斯分布合情合理。而且根据上面的介绍,等价于,我们本来就应该得到一个高斯分布,根据这个高斯分布的参数得到重建过程中状态和噪声的比重。
显然我们不能直接推理出,于是我们需要学习一个模型来拟合,可以表示为
那么接下来目标明确,就是要学习两个网络。其实到这里就停下来也不是不行,我们直接预测这两个网络(接着往后看,其实只需要预测一个均值网络),但是总觉得不大好,因为怎么确定这两个网络的ground_truth,你损失函数怎么设计呢,所以接下来应该让和我们算的那一堆扯上关系,我们才能设计和之间的损失函数进行训练。
这个时候继续盯着是看不出什么东西的,但是有的大佬发现我们可以看看,他发现可以表示成下面这种形式
推理过程如下
等式的第一步,就是贝叶斯公式,将这个概率直接化为三个已知量
其中根据马尔可夫性质就等于 ,那么上面的式子就可以直接用高斯分布的式子去计算了,然后我们要凑高斯分布的形式,即
然后对应求出和。上面的式子已经将平方项和一次项化简了,根据
得到
这里已经表达为常数了,而里面还有一个,注意我们这是采样过程,是从到0变化的,所以是已知的,是未知的。其实到这里也可以停下来了,这里我们已经将表示为,所以我们可以通过训练一个网络预测,他的ground truth我们也知道,但是这样的话不就直接生成了样本吗?确实,这样相当于直接预测了样本,但是这样预测的结果很差,毕竟你没有一步步采样的,这样就和单层VAE差不多了。
所以再进一步,这里用到扩散过程的结论,不过上面扩散过程的结论是把用表示的,稍微换一下,带入得
这里唯一的变数就是,其实这就是DDPM要训练的东西,这个东西就是噪声预测网络,也对应了伪代码采样过程的公式,注意伪代码使用了参数重整化采样。
到这里时真的可以停下来了,采样过程的公式已经明晰了,就根据上面的公式一步步推出,结合参数重整化,一步步采样出原图即可。不嫌弃的话,扩散过程的损失函数可以直接理解为作者选了一个MSE作为误差函数。
但是这样是不严谨的,你凭什么选MSE作为误差函数呢?
损失函数证明
接下来是最一头雾水的证明了,这个证明其实在VAE里面也有。这里我们先把上面推导出来的表达式,以及训练对象是的结论放一边,我们只讨论需要学习的模型,这个模型是一个PDF,其拟合的对象是,也就是采样过程中的PDF。
记得前面说过的似然法吗,这里再理清一下思路,似然法是在知道事情发生之后,希望我们概率模型输出的概率值越大越好,所以当我们采样一个后,我们希望越大越好。这里可能会有疑惑的点是不是建模的条件概率吗,条件呢?我们应该注意PDF中自变量是一个事件,他不是也一般函数里的数字,我们可能还要讨论一下自变量的定义域什么的。因为我们已经采样到了,这个事件已经发生了,条件不条件的就不重要了,我们只希望他发生的概率最大,所以这里记为是没有问题的。
另外这里采样并不是说只采样一张图片,而是采样一批样本。毕竟大家概率论上课时学的概率似然也不是只采样一个样本,可以理解为一批样本的联合概率,反正这里的数学证明都是抽象的。
证明的第一步就是写出似然函数,当然我们肯定是写不出来的,因为神经网络训练的东西怎么写解析式呢,我们只知道一个符号,因此我们需要求其下界。实际操作中一般取负对数似然,也就是求负对数似然上界
最后的结果中的q是指。这个等式涉及到KL散度的定义,KL散度计算时需要输入两个概率分布,其计算公式为
它用来度量基于某一个分布来编码另一个分布,又称为相对熵,可以简单理解为两个分布之间的差别,他的一个重要性质是KL散度的值为非负数,当且仅当两个分布相同时为0。如果p、q是条件概率,上面的式子可以进一步变形
不要问我为什么这里都是z和x,一开始就说了公式都是偷的,不是自己敲的,凑活看吧
由于求负对数似然时引入的是到的联合概率分布,联合概率分布就把所有概率乘起来就可以了,即
可以上面KL散度中的看作,看作,结合期望公式很容易的最开始的不等式。对于那个不等式,左右两边同时乘以,将不等式右边记为,整理一下,得到
对上面这个式子不理解的话,就把期望写成积分形式,乘一下,结合条件概率公式即可。公式实在是懒得敲。
其实就是p、q之间的交叉熵,看不出来可以写成积分的形式看,交叉熵是什么应该不用介绍吧。上面是从似然的角度推导的,当然我们也可以从交叉熵的角度推导交叉熵上界,过程如下
一样的看到没。
接下来进一步优化这个。为了将方程中的每个项转换为可解析计算的,可以将目标进一步重写为几个KL散度和熵项的组合。
上面的式子在推导过程中用到了下面的结论
这个结论应该挺显然的,其他的步骤就是数学计算了。结果上面的计算,被分为了三个部分
首先明确一点对于每个,可以调整的参数只存在于中,我们希望这个上界越小越好。接下来逐项分析这个上界,期望最小化这个上界。
的最小化
对于,由于是服从各向同性高斯分布,固定了,所以是常数。当然不是说是常数我们就不管了,我们需要选择合适的参数使尽可能小。
的最小化
对于,其实细心的话可以发现,是可以考虑到里面去的,可以把带到里面,然后把KL散度写开看看。那为什么单独写呢,因为前面是在计算KL散度,没有问题,但是这里要如果真要算似然值的话,是要算概率的。我们知道输出的是图像,是离散的,而我们设计的 是一个连续的PDF,算概率要积分,单点的概率是0,这个似然值是算不了的,所以要特殊处理一下。
具体来说,依然假设,其中是神经网络预测的均值,但是由于是离散的,为了能算出这个概率,进而算出似然值,我们将这个概率强行写成积分
上面的指的是图片的第个像素,做上面的处理之前,作者假设图片每个像素是从 范围的整数线性缩放到 范围内的数。这里相当于把每个像素近似了一个积分区间,方便计算似然值,然后我们就可以用数值方法优化这里面的。
的最小化
是两个高斯分布之间的KL散度,这个可以自己推一下,假设两个高斯分布的均值和方差分别是我们有
所以
注意上面的是带下来的期望下标换了是因为我们把q给拆了,下标肯定也要拆,我们就看括号里的东西就行。同时注意到p、q的方差都是常数,把常系数丢掉,就有
这样就成功推导出了伪代码中的损失函数。可以看到这个损失函数其实是从似然法或者交叉熵的角度推出来的,只是最后推理出来的形式和MSE接近
优化过程
总体的优化过程基本就是伪代码的train过程,其梯度传播对于 和 其实是一样的,只是要多一些操作,所以伪代码没写也可以理解。
总结
以上就是基础DDPM涉及到的数学推导的介绍。一步步看下来,其实比较难想的主要是两个地方,一是采样过程的估计,第二个就是负对数似然上界的求法,这个确实不是一般人想得出来的。除此之外的一个难点就是符号用的确实很乱,特别是关于期望的符号的不熟练,要多看几遍,看不懂就自己把期望写成积分形式,总能看懂的。